In the latest release, the TaggedImport has now more options to select and reduce the mass of connections, and the thesaurus sample application is improved with a new sample dataset and also with more filtering options.
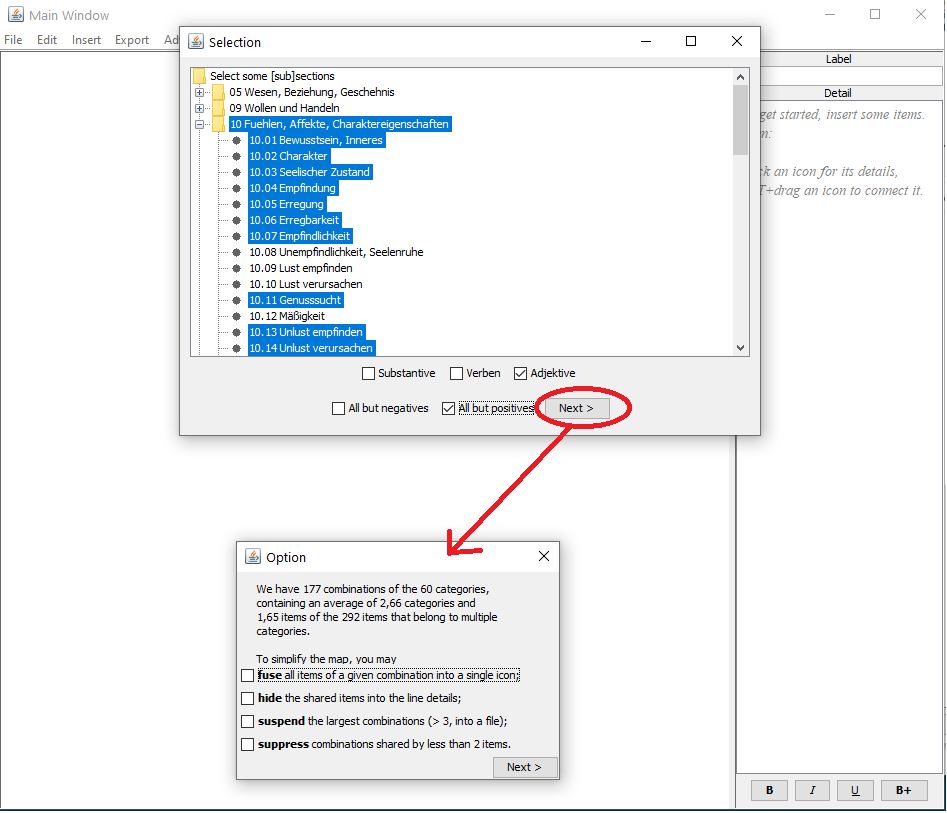
In all tagged imports (input lines consisting of term TAB tag), you can now
- fuse multiple items into one,
- hide many item nodes into the connector line,
- suspend the big, most connected, items for later processing them separately,
- and suppress the small nodes altogether.
In the thesaurus sample importer (now: Insert > Import Wizard > Thesaurus tags), you can choose between an English and a German dataset, and in addition to selecting subsections and parts of speech, you can filter out all negative or all positive terms, if applicable as in the German sample, or the left or right column, from some Roget’s English sections.
Purpose
These improvements should enable the user to play with larger datasets and max out the complexity of a map, to find out how many connections can be shown without losing a sense of orientation and gestalt, with identifiable connector lines, rather than an amorphous (while impressively colored) cloud of tiny dots with random sampling just for marveling at.
Note that the current approach requires the user to manually fine-tune the map and simulate what the so-called ‘force-directed’ layout algorithms do automatically. (Please tell me if you know of such an algorithm that satisfyingly preserves the core circle.)
Also note that the new functions are currently only available in the Java (.jar) distribution file, not yet in the .dmg or .msi files.
One thought on “More filtering options”